
À medida que as preocupações com segurança cibernética, privacidade de dados e soberania tecnológica aumentam, mais empresas e governos estão reconhecendo a importância de ter controle direto sobre seus dados. Esse controle é alcançado por meio da repatriação de dados, que envolve trazer informações sensíveis de volta para servidores e data centers nacionais.
O que é Repatriação de Dados?
Resumidamente, a repatriação de dados é o processo de transferir dados de servidores ou data centers estrangeiros de volta para o país de origem. Isso é feito, principalmente, para garantir maior controle, segurança e conformidade com regulamentações locais. Ao repatriar os dados, as empresas podem armazenar e gerenciar suas informações sensíveis em conformidade com as leis e regulamentos do país onde estão sediadas, reduzindo assim o risco de violações de segurança e conformidade.
Vantagens da Adoção de Repatriação de Dados
A repatriação de dados oferece várias vantagens estratégicas que podem beneficiar tanto empresas quanto governos, especialmente no contexto tecnológico atual. Vamos explorar essas vantagens em detalhe:
Maior Controle e Segurança de Dados
Uma das vantagens mais evidentes da repatriação de dados é o aumento do controle sobre as informações críticas das organizações. Ao trazer os dados de volta para casa, as empresas podem exercer maior supervisão sobre como eles são gerenciados, armazenados e protegidos. Com controle total, as organizações podem garantir que apenas as pessoas autorizadas tenham acesso às informações sensíveis, diminuindo os riscos de uso indevido e exposição de dados. Manter os dados dentro das fronteiras nacionais pode reduzir os riscos de exposição a violações de segurança, espionagem e acesso não autorizado.
Conformidade com Regulamentações
A repatriação contribui significativamente para uma maior conformidade com regulamentações e leis locais e internacionais. Muitos países têm leis específicas que regem como os dados dos cidadãos devem ser tratados e protegidos. Ao armazenar os dados dentro das fronteiras nacionais, as empresas podem garantir que estão em conformidade com as regulamentações do seu país, evitando potenciais conflitos com outras legislações. A conformidade regulatória não apenas reduz o risco de penalidades legais e financeiras, mas também aumenta a confiança dos clientes e parceiros.
Soberania Tecnológica e Independência Nacional
Repatriar dados envolve a capacidade de um país ou organização proteger seus sistemas de informação, dados e infraestrutura digital contra influências externas indesejadas, garantindo assim sua integridade, segurança e confiabilidade. Isso fortalece a soberania tecnológica, permitindo que as empresas e governos mantenham o controle total sobre suas informações críticas e infraestrutura digital.
Resiliência Operacional
A repatriação de dados garante que as organizações possam enfrentar e superar desafios e interrupções de forma eficaz e eficiente. Ao adotar uma abordagem proativa, é possível minimizar riscos e garantir a continuidade das operações. Isso inclui a capacidade de recuperar rapidamente os dados e continuar as operações mesmo diante de crises ou falhas de infraestrutura.
Redução de Custos a Longo Prazo
Embora a repatriação de dados envolva custos iniciais de migração, por exemplo, o potencial de economias a longo prazo é um dos principais fatores que impulsionam as empresas a optar por essa estratégia. Ao repatriar, as empresas podem reduzir significativamente os custos contínuos associados à manutenção de infraestruturas de armazenamento de dados em servidores internacionais. Isso inclui economias em taxas de serviço, manutenção e suporte, além de evitar custos associados a conformidade com regulamentações internacionais.
Aumento da Confiança e Reputação
A conformidade regulatória e a segurança aprimorada resultantes da repatriação de dados não apenas reduzem os riscos de penalidades legais e financeiras, mas também aumentam a confiança dos clientes e parceiros. Empresas que demonstram um compromisso com a proteção de dados e a conformidade regulatória ganham uma reputação positiva, o que pode ser um diferencial competitivo significativo.
Tendências Futuras
Regulamentações mais rigorosas
À medida que os governos ao redor do mundo implementam leis de privacidade de dados mais rigorosas, a necessidade de repatria-los para garantir conformidade continuará a crescer.
Adoção de tecnologias de nuvem híbrida
As empresas estão cada vez mais adotando modelos de nuvem híbrida que combinam infraestruturas locais com serviços de nuvem pública, facilitando a repatriação de dados e garantindo flexibilidade e segurança.
Desenvolvimento de infraestruturas locais
Investimentos em data centers locais e infraestrutura de TI aumentarão, permitindo uma transição mais suave para a repatriação.
Conclusão
A repatriação de dados representa uma estratégia essencial no atual panorama tecnológico, oferecendo às empresas e governos maior controle, segurança e conformidade regulatória.
É crucial que as organizações estejam cientes dos desafios envolvidos, como os custos iniciais e a complexidade do processo de migração. Planejamento cuidadoso, uso de tecnologias adequadas e consideração das regulamentações internacionais são essenciais para uma transição bem-sucedida e a garantia de que será uma decisão financeiramente sensata a longo prazo.
Olhando para o futuro, a repatriação de dados continuará a ser uma prioridade à medida que as regulamentações de privacidade de dados se tornarem mais rigorosas e as preocupações com a soberania tecnológica aumentarem. A adoção de práticas sustentáveis e a construção de uma infraestrutura tecnológica robusta localmente, também desempenharão um papel crucial nesse processo.
Conte conosco!
Oferecemos consultoria especializada em PostgreSQL para ajudar empresas a encontrarem um crescimento tecnológico sustentável através de uma combinação de expertise técnica e visão de negócios, que vai do panorama estratégico até a implementação operacional. Estamos prontos para oferecer suporte contínuo, assegurando que seus dados permaneçam seguros e suas operações não parem.





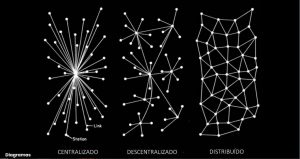





 Figura 1: Uma ilustração de um espaço vetorial multidimensional contínuo representando frases individuais. Fonte: [2]
Figura 1: Uma ilustração de um espaço vetorial multidimensional contínuo representando frases individuais. Fonte: [2]



